Security Posts
New VPN Risk Report: 56% of Enterprises Attacked via VPN Vulnerabilities
Virtual private networks (VPNs) have long provided remote access for enterprises. However, after a year full of high-profile exploits of severe and zero-day VPN vulnerabilities, including ones requiring emergency CISA directives to disconnect VPN services, enterprises are reconsidering. Many are rethinking workforce connectivity strategies and moving to zero trust architecture as a secure VPN alternative.
In fact, 91% of enterprises are concerned that VPNs will compromise their security.
Released today, the Zscaler ThreatLabz 2024 VPN Risk Report sheds light on critical VPN trends and explores solutions to secure remote users. Cybersecurity Insiders and Zscaler surveyed 647 IT professionals and cybersecurity experts on the shifting security, management, and user experience challenges of VPN technologies. These include the risks VPNs may present to an organization’s security posture around lateral movement, third-party access, and vulnerability to attacks like ransomware.
Overall, the findings paint a clear picture. Enterprises show stark concerns around the security risks of VPN solutions, even as they reach a strong consensus around zero trust strategies and make concrete plans to adopt zero trust network access (ZTNA). Organizations also agree hosting VPN infrastructure in the cloud is against the principles of zero trust and does not provide the same level of security or user experience as ZTNA.
Download the Zscaler ThreatLabz 2024 VPN Risk Report to uncover enterprise perspectives and expert guidance around the risks of VPN.
Key FindingsVPN attacks are on the rise. 56% of organizations experienced one or more VPN-related cyberattacks in the last year—up from 45% the year before. This highlights the growing frequency and sophistication of attacks targeting VPNs.
The vast majority are shifting to zero trust. 78% of organizations plan to implement zero trust strategies in the next 12 months. Meanwhile, 62% of enterprises agree that VPNs are anti-zero trust.
Most have doubts about VPN security. 91% of respondents expressed concerns about VPNs compromising their IT security environment. Recent breaches illustrate the risks of maintaining outdated or unpatched VPN infrastructures.
VPNs are no match for ransomware, malware, and DDoS. Respondents identified ransomware (42%), malware (35%), and DDoS attacks (30%) as the top threats exploiting VPN vulnerabilities, underscoring the breadth of risks organizations face due to inherent weaknesses in traditional VPN architectures.
The risk of lateral movement can’t be ignored. 53% of enterprises breached via VPN vulnerabilities say threat actors moved laterally, demonstrating containment failures at the initial point of compromise that underscore the risks of traditional, flat networks.
Almost everyone has concerns about third-party risk. Since VPNs provide full network access, 92% of respondents are concerned about third parties with VPN access serving as potential backdoors into their networks.
Rising VPN Attacks, CVEs, and Enterprise ConcernsOverall, a staggering 56% of organizations reported cyberattacks that exploited VPN vulnerabilities within the past year, marking a significant increase from the previous year (45%). Even more concerning, 41% of organizations reported experiencing two or more VPN-related attacks, highlighting the existence of severe security gaps that need immediate attention.
Figure 1: Enterprises that have experienced an attack that targeted VPN vulnerabilities in the past year.
This rise in VPN-related attacks is not without context. In the past year, we’ve seen a string of zero-day and high-severity VPN vulnerabilities come to light. This trend has revealed that, from an architectural point of view, VPN-based networks are vulnerable to a single point of failure that allows threat actors to move laterally on the network, discover crown jewel applications, and steal sensitive data.
Indeed, most survey respondents who experienced VPN-related breaches reported that attackers moved laterally on their networks.
Figure 2: A string of high-profile CVEs impacting VPN in the last year.
Enterprise trust in the security of VPNs is low. Overall, 91% of companies have concerns that VPNs may jeopardize the security of their environments.
Figure 3: Enterprise concerns that VPN may jeopardize the security of their environment.
Growth in Zero Trust AdoptionIn parallel with, or because of, the security concerns of VPN, enterprises show a strong consensus around the adoption of zero trust strategies for secure connectivity. In fact, 62% of enterprises see VPN technology as incompatible with zero trust strategies.
Figure 4: Enterprise views on VPN as compatible with zero trust strategies.
Meanwhile, enterprises are actively adopting zero trust strategies as enthusiasm for VPN wanes. On the whole, 78% of enterprises plan to implement zero trust strategies within the next 12 months, while 31% are actively implementing zero trust strategies today.
Figure 5: Enterprise adoption of zero trust strategies.
As the number of high-profile security vulnerabilities associated with VPNs continues to rise, businesses should anticipate a corresponding rise in security incidents related to VPNs. As a result, enterprises will increasingly look to ZTNA as a replacement for VPN and a way to fundamentally improve their security posture.
Our ZTNA solution, Zscaler Private Access (ZPA) provides comprehensive security for users connecting to private applications regardless of their location, from any device. With ZPA, applications are hidden from internet exposure, making it difficult for attackers to find and target them. Our inline traffic inspection detects malicious activities to prevent compromise and data exfiltration. ZPA is able to limit the blast radius with AI-powered user-to-app segmentation and integrated deception.
For the full report insights, including best-practice guidance on mitigating VPN risks and predictions for 2024 and beyond, download your copy of the Zscaler ThreatLabz 2024 VPN Risk Report with Cybersecurity Insiders today
Categories: Security Posts
Infocon: green
ISC Stormcast For Tuesday, May 7th, 2024 https://isc.sans.edu/podcastdetail/8970
Categories: Security Posts
ISC Stormcast For Tuesday, May 7th, 2024 https://isc.sans.edu/podcastdetail/8970, (Tue, May 7th)
(c) SANS Internet Storm Center. https://isc.sans.edu Creative Commons Attribution-Noncommercial 3.0 United States License.
Categories: Security Posts
Cyberguardian: Un podcast de Ciberseguridad, Hacking, Privacidad & IA
Ayer se publicó el episodio del podcast de Cyberguardian con Sara Lasso de la Vega y Eduardo Castillo - y promovido por OPSWAT - que grabé la semana pasada. Es el tercero de la serie que han grabado hasta el momento, y en esta sesión de 40 minutos hablamos de lo que os podéis imaginar: Ciberseguridad, Privacidad, Hacking & Inteligencia Artificial como aderezo a todo este mundo.
Figura 1: Cyberguardian: Un podcast de ciberseguridad de OPSWAT.Con Sara Lasso de la Vega, Eduardo Castillo y Chema Alonso.
El podcast ya lo tenéis disponible en la página web de podcasts de Cyberguardian de Capital Radio, donde podéis ver no solo el mío, sino todos los que se han hecho hasta el momento.
Figura 2: Lista de episodios de Cyberguarian en Capital Radio, para escuchar, compartir o descargar.
Entre otros, uno que le han hecho a Juanjo García Cabrera, que trabaja en el equipo de Microsoft Azure en España como especialista en ciberseguridad.
Figura 3: Contactar con Juan García Cabrera de Microsoft
Yo he subido el episodio del podcast a mi canal de Youtube, donde ya lo podéis escuchar completo. Ahora o cuando tengas tiempo, que se va a quedar ahí como todos los que tienes ya publicados en mi canal.
Figura 4: Cyberguardian con Sara Lasso, Edu Castillo y Chema Alonso
Y si quieres participar en este podcast o proponerles alguna colaboración, puedes contactar con Sara Lasso de la Vega en su perfil público de MyPublicInbox, donde seguro que te atiende encantada.
Figura 5: Contactar con Sara Lasso de la Vega
Y esto es todo por hoy, que con todo lo que dije en ese podcast tienes suficiente como para entretenerte un rato con la Ciberseguridad y la Inteligencia Artificial, que de eso se trata en El lado del mal. Que tengas un feliz martes.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)
Sigue Un informático en el lado del mal RSS 0xWord
- Contacta con Chema Alonso en MyPublicInbox.com
Figura 1: Cyberguardian: Un podcast de ciberseguridad de OPSWAT.Con Sara Lasso de la Vega, Eduardo Castillo y Chema Alonso.
El podcast ya lo tenéis disponible en la página web de podcasts de Cyberguardian de Capital Radio, donde podéis ver no solo el mío, sino todos los que se han hecho hasta el momento.
Figura 2: Lista de episodios de Cyberguarian en Capital Radio, para escuchar, compartir o descargar.
Entre otros, uno que le han hecho a Juanjo García Cabrera, que trabaja en el equipo de Microsoft Azure en España como especialista en ciberseguridad.
Figura 3: Contactar con Juan García Cabrera de Microsoft
Yo he subido el episodio del podcast a mi canal de Youtube, donde ya lo podéis escuchar completo. Ahora o cuando tengas tiempo, que se va a quedar ahí como todos los que tienes ya publicados en mi canal.
Figura 4: Cyberguardian con Sara Lasso, Edu Castillo y Chema Alonso
Y si quieres participar en este podcast o proponerles alguna colaboración, puedes contactar con Sara Lasso de la Vega en su perfil público de MyPublicInbox, donde seguro que te atiende encantada.
Figura 5: Contactar con Sara Lasso de la Vega
Y esto es todo por hoy, que con todo lo que dije en ese podcast tienes suficiente como para entretenerte un rato con la Ciberseguridad y la Inteligencia Artificial, que de eso se trata en El lado del mal. Que tengas un feliz martes.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)
Sigue Un informático en el lado del mal RSS 0xWord
- Contacta con Chema Alonso en MyPublicInbox.com
Categories: Security Posts
Novel attack against virtually all VPN apps neuters their entire purpose
Enlarge (credit: Getty Images)
Researchers have devised an attack against nearly all virtual private network applications that forces them to send and receive some or all traffic outside of the encrypted tunnel designed to protect it from snooping or tampering.
TunnelVision, as the researchers have named their attack, largely negates the entire purpose and selling point of VPNs, which is to encapsulate incoming and outgoing Internet traffic in an encrypted tunnel and to cloak the user’s IP address. The researchers believe it affects all VPN applications when they’re connected to a hostile network and that there are no ways to prevent such attacks except when the user's VPN runs on Linux or Android. They also said their attack technique may have been possible since 2002 and may already have been discovered and used in the wild since then.
Reading, dropping, or modifying VPN traffic
The effect of TunnelVision is “the victim's traffic is now decloaked and being routed through the attacker directly,” a video demonstration explained. “The attacker can read, drop or modify the leaked traffic and the victim maintains their connection to both the VPN and the Internet.”Read 5 remaining paragraphs | Comments
{kind=link}
Categories: Security Posts
New Microsoft AI model may challenge GPT-4 and Google Gemini
Enlarge / Mustafa Suleyman, co-founder and chief executive officer of Inflection AI UK Ltd., during a town hall on day two of the World Economic Forum (WEF) in Davos, Switzerland, on Wednesday, Jan. 17, 2024. Suleyman joined Microsoft in March. (credit: Getty Images)
Microsoft is working on a new large-scale AI language model called MAI-1, which could potentially rival state-of-the-art models from Google, Anthropic, and OpenAI, according to a report by The Information. This marks the first time Microsoft has developed an in-house AI model of this magnitude since investing over $10 billion in OpenAI for the rights to reuse the startup's AI models. OpenAI's GPT-4 powers not only ChatGPT but also Microsoft Copilot.
The development of MAI-1 is being led by Mustafa Suleyman, the former Google AI leader who recently served as CEO of the AI startup Inflection before Microsoft acquired the majority of the startup's staff and intellectual property for $650 million in March. Although MAI-1 may build on techniques brought over by former Inflection staff, it is reportedly an entirely new large language model (LLM), as confirmed by two Microsoft employees familiar with the project.
With approximately 500 billion parameters, MAI-1 will be significantly larger than Microsoft's previous open source models (such as Phi-3, which we covered last month), requiring more computing power and training data. This reportedly places MAI-1 in a similar league as OpenAI's GPT-4, which is rumored to have over 1 trillion parameters (in a mixture-of-experts configuration) and well above smaller models like Meta and Mistral's 70 billion parameter models.Read 3 remaining paragraphs | Comments
{kind=link}
Categories: Security Posts
Key Insights from the OpenText 2024 Threat Perspective
As we navigate through 2024, the cyber threat landscape continues to evolve, bringing new challenges for both businesses and individual consumers. The latest OpenText Threat Report provides insight into these changes, offering vital insights that help us prepare and protect ourselves against emerging threats. Here’s what you need to know:
The Resilience of Ransomware
Ransomware remains a formidable adversary, with groups like LockBit demonstrating an uncanny ability to bounce back even after significant law enforcement actions. Despite a recent crackdown that saw authorities dismantle its infrastructure, LockBit swiftly resumed operations, even taunting law enforcement agencies in the process. This adaptability highlights how resourceful ransomware groups have become, enabling them to evade detection and persistently challenge defenders.
For businesses, this means implementing a comprehensive incident response plan that includes secure, immutable backups and regular testing to ensure rapid recovery in the event of an attack. Consumers should also take measures like frequently backing up their data to an external drive or cloud solution. This resilience requires ongoing vigilance and robust security measures for everyone involved.
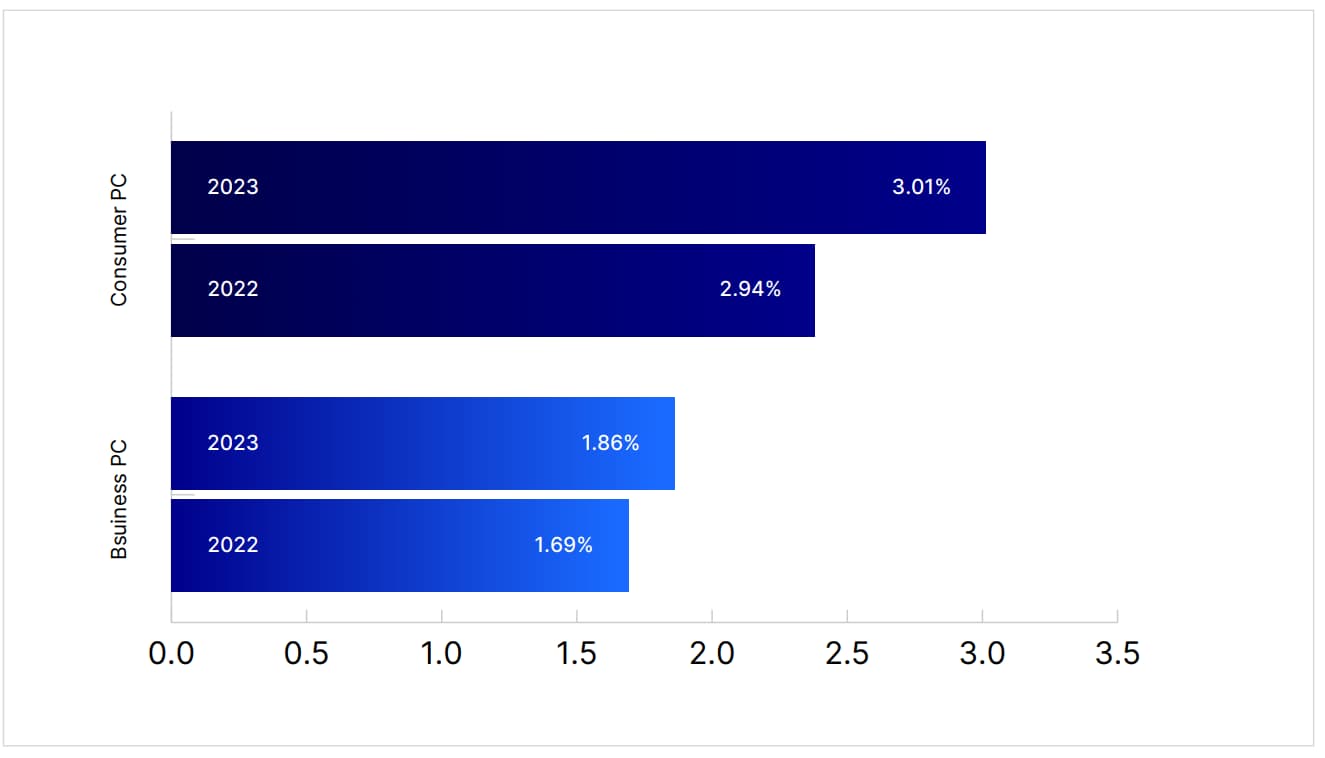
Malware Infections on the Rise
For the first time in years, malware infection rates are rising among both businesses and consumers. The uptick is primarily attributed to attackers leveraging advanced tools like generative artificial intelligence (AI), which helps them craft malware that’s more sophisticated and adaptive. Malware variants are becoming more difficult to detect, and infection methods are increasingly creative, such as using enticing email attachments or redirecting users to malicious sites via QR codes.
This new wave of malware infections serves as a stark reminder for businesses and individuals to strengthen their cyber defenses. Keep all devices updated with the latest security patches, and use reputable antivirus solutions that can block suspicious downloads and identify malicious software. Additionally, be wary of unexpected attachments or links and avoid clicking on anything that looks suspicious.
Phishing Gets Personal
Phishing attacks are becoming more sophisticated, thanks to tools like generative AI, which enable attackers to personalize their campaigns for maximum impact. What was once a clear distinction between mass phishing emails and more targeted spear-phishing attempts is now blurring, making it harder to distinguish between the two. Attackers can craft convincing emails that mimic legitimate brands, logos, and domains to trick unsuspecting victims into providing sensitive information or clicking malicious links.
For both businesses and consumers, this trend emphasizes the need for increased vigilance and cybersecurity awareness. Educate yourself on common phishing tactics and train employees to recognize fraudulent emails. Multi-factor authentication (MFA) can add a vital layer of protection, and carefully inspect email addresses and links before taking any action.
The Critical Role of Cyber Resilience
The report underscores the importance of adopting a multi-layered defense strategy to mitigate the impact of these evolving threats. Cyber resilience involves proactive measures to prevent attacks while also ensuring you can quickly recover if a breach occurs. For businesses, this means implementing strong antivirus software, endpoint protection solutions, and regular software updates. For consumers, being alert to suspicious emails, using secure passwords, and frequently backing up data is crucial.
A multi-layered approach integrates different layers of defense, making it much harder for an attacker to compromise all systems simultaneously. Combine antivirus tools with DNS protection, endpoint monitoring, and user training for comprehensive protection.
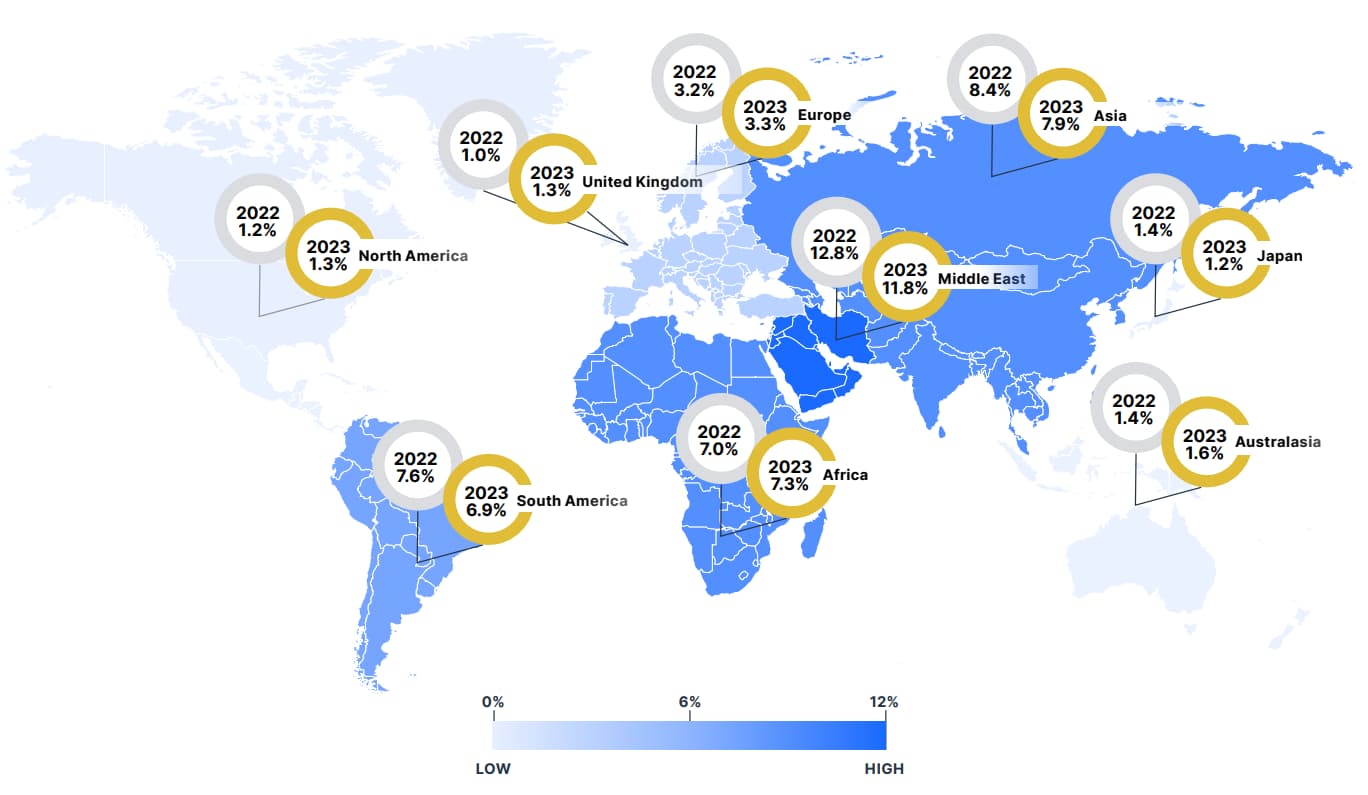
Regional Disparities in Cyber Threats
Geographical factors significantly influence the prevalence and nature of cyber threats. The report identifies regions like Asia, Africa, and South America facing higher infection rates than North America and Europe, partly due to differing economic conditions, cybersecurity maturity, and regulatory environments. Malware campaigns are often tailored to exploit regional nuances, such as the availability of local payment methods or common software vulnerabilities.
Businesses operating globally should adapt their cybersecurity strategies to account for these disparities, ensuring protections are tailored to local risks. Similarly, consumers should stay updated on the regional trends to better prepare for prevalent scams and threats in their area.
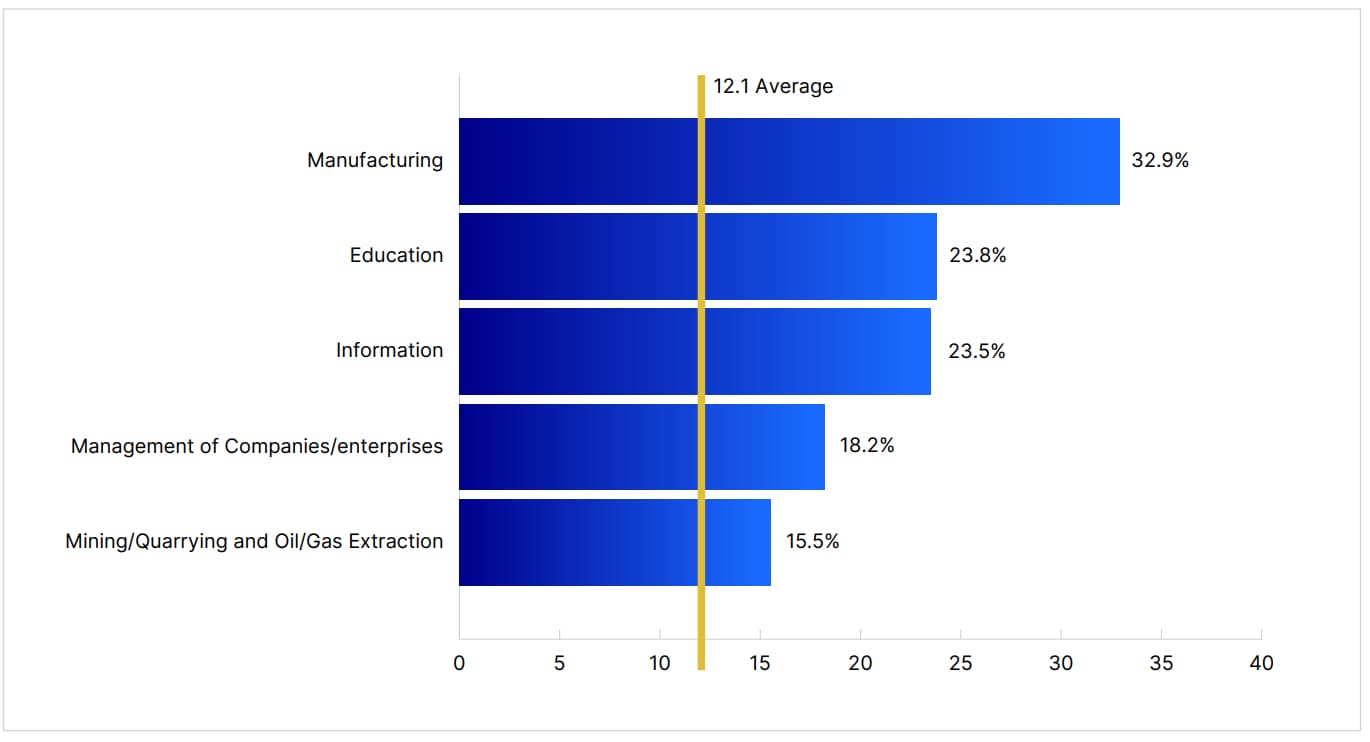
Industry-Specific Risks
This chart shows the percentage of businesses in each industry that encountered at least one malware infection over the past year
Specific industries like manufacturing, education, and healthcare are frequently targeted due to the valuable data they hold and the potential disruption caused by successful attacks. Manufacturing is particularly vulnerable to ransomware due to the high cost of production stoppages, which can prompt quicker ransom payments. Educational institutions, on the other hand, often have limited cybersecurity budgets, leaving them vulnerable to malware and phishing attacks that can compromise student and faculty data.
While businesses in these industries must enhance their cyber defenses and train staff accordingly, consumers should also be aware of how these attacks could indirectly impact them. For instance, a ransomware attack on a healthcare provider could lead to data breaches exposing patient information.
Recommendations for Enhancing Cybersecurity
{kind=link}
{kind=link}
{kind=link}
- Implement Advanced Email Security: Use systems that can effectively block malicious attachments and links to protect against phishing.
- Stay Updated with Regular Patches: Keeping your software up-to-date is a critical step in protecting against vulnerabilities that could be exploited by attackers.
- Invest in Comprehensive Cybersecurity Training: Both businesses and individual users should engage in ongoing education on cybersecurity best practices to recognize and mitigate threats.
- Adopt Robust Backup Solutions: Ensure that all important data is backed up regularly and securely. This not only protects information but also minimizes disruption in the event of a cyber attack.
Categories: Security Posts
HijackLoader Updates
IntroductionHijackLoader (a.k.a. IDAT Loader) is a malware loader initially spotted in 2023 that is capable of using a variety of modules for code injection and execution. It uses a modular architecture, a feature that most loaders do not have – which we discussed in a previous HijackLoader blog. ThreatLabz researchers recently analyzed a new HijackLoader sample that has updated evasion techniques. These enhancements aim to increase the malware’s stealthiness, thereby remaining undetected for longer periods of time. HijackLoader now includes modules to add an exclusion for Windows Defender Antivirus, bypass User Account Control (UAC), evade inline API hooking that is often used by security software for detection, and employ process hollowing.In addition, HijackLoader’s delivery method involves the use of a PNG image, which is decrypted and parsed to load the next stage of the attack. ThreatLabz observed HijackLoader being used to drop multiple malware families, including Amadey, Lumma Stealer, Racoon Stealer v2, and Remcos RAT.In this blog post, we discuss HijackLoader updates and provide a Python script to extract the malware configuration and modules from HijackLoader samples. Additionally, we delve into the malware families deployed by HijackLoader from March 2024 to April 2024.Key TakeawaysHijackLoader is a modular malware loader that is used to deliver second stage payloads including Amadey, Lumma Stealer, Racoon Stealer v2, and Remcos RAT.HijackLoader decrypts and parses a PNG image to load the next stage.HijackLoader now contains the following new modules: modCreateProcess, modCreateProcess64, WDDATA, modUAC, modUAC64, modWriteFile, and modWriteFile64.HijackLoader has additional features like dynamic API resolution, blocklist process checking, and user mode hook evasion using Heaven's Gate.ThreatLabz researchers created a Python script to decrypt and decompress the second stage and extract all HijackLoader modules.Technical AnalysisThe following sections focus on the new changes to HijackLoader.First stageThe purpose of the loader’s first stage is to decrypt and decompress the HijackLoader modules, including the second stage (ti64 module for 64-bit processes and ti module for 32-bit processes), and execute the second stage.The first stage resolves the APIs dynamically by walking the process environment block (PEB) and parsing the Portable Executable (PE) header. The loader uses the SDBM hashing algorithm below to resolve APIs. def SDBMHash(apiName):
finalHash = 0
for i in apiName:
finalHash = (finalHash*0x1003F) & 0xFFFFFFFF
finalHash = (finalHash + ord(i)) & 0xFFFFFFFF
return finalHashUsing the SDBM hash algorithm above, the loader resolves the WinHTTP APIs to check for an internet connection. This is achieved with the following URL:https://apache.org/logos/res/incubator/default.pngThe loader repeats this process until there is an internet connection. After that, HijackLoader decrypts embedded shellcode by performing a simple addition operation with a key. It then sets the execute permission using VirtualProtect for the decrypted shellcode and calls the start address of the shellcode.Blocklist processesThe shellcode uses the SDBM hash algorithm again to resolve additional APIs. After that, the shellcode uses the RtlGetNativeSystemInfo API to check for blocklisted processes running on the system. In previous versions of HijackLoader, the loader checked for five processes related to antivirus applications. Now, the code only checks for two processes.The names of current running processes are converted to lowercase letters and the SDBM hashing algorithm is compared with the hashes of the two processes. If these values match, execution is delayed using the NtDelayExecution API. Information for the two blocklisted processes can be found in the table below.Hash ValueProcess NameDescription5C7024B2avgsvc.exeThe avgsvc.exe file is a software component of AVG Internet Security.B03D4537UnknownN/ATable 1: Processes blocklisted by HijackLoader.Note that the AVG process was also previously blocklisted by earlier versions of HijackLoader.Second stage loading processThere are two methods that HijackLoader uses to load the second stage, both of which are embedded in the malware’s configuration. HijackLoader retrieves a DWORD from the configuration at offset 0x110 and XOR’s the value with a DWORD from the configuration at offset 0x28. Let's refer to the result of this XOR as the value “a”.The malware loads a copy of itself into memory using GlobalAlloc and ReadFile. Then it reads a DWORD from the configuration at offset 0xC and adds this value to the address where the malware file was loaded into memory, and then reads a DWORD from this address. Let's call this value “b”. If “a” and “b” do not match, a PNG file is downloaded and used to load the second stage. If “a” and “b” match, an embedded PNG is used to load the second stage.The image below shows an example of an embedded PNG when rendered using an image viewer.Figure 1: An embedded PNG image containing the encrypted modules used by HijackLoader in a PNG viewer.PNG payloadThe screenshot below displays the decompiled HijackLoader code that checks whether the PNG is embedded within the file or if it needs to be downloaded separately.Figure 2: The decompiled output of HijackLoader to find if the PNG is embedded or if it should be downloaded.If the PNG is embedded, the malware starts searching for the PNG image with the following bytes: 49 44 41 54 C6 A5 79 EA. This contains the IDAT header 49 44 41 54 and magic header C6 A5 79 EA. The logic replicated below in Python shows how the malware finds the IDAT header followed by the magic header.checkFlag = 0
with open(malware_file, "rb") as input_file:
input_file.seek(0)
file = input_file.read()
offset = 0
try:
resultOffsetNextByte = file.index(b'\x49\x44\x41\x54\xC6\xA5\x79\xEA', offset + 1)
print("Found Corect PNG Image")
checkFlag = 1
except ValueError:
print('Could not Find PNG with Correct Header')The screenshot below shows the IDAT header followed by the magic header C6 A5 79 EA.Figure 3: The format of the IDAT header.If the PNG needs to be downloaded, the URL is decrypted from the configuration using a simple XOR cipher. Following that, the WinHTTP library is utilized to download the PNG from the decrypted URL.There are multiple encrypted blobs in the PNG file. Each encrypted blob is stored in the format Blob size:IDAT header. Each of the encrypted blobs can be found by searching for the IDAT header. The size of each encrypted blob is parsed and data of this size following the header is appended to a new memory address. When the total size is reached, the encrypted data is decrypted using a simple XOR cipher with the key: 32 A3 49 B3 (which is a DWORD that follows the MAGIC Header). Then, the decrypted blob is decompressed using the LZNT1 algorithm.This decompressed data contains the modules and configurations used to load the second stage. The offset at 0xF4 of the decompressed data contains a DLL name (in this specific case pla.dll) that is loaded into memory. The modules are then parsed to locate the ti module (by name) using the SDBM hashing algorithm. Then, the ti module is copied to the DLL’s BaseOfCode field and is executed.The screenshot below shows the decompiled output for the injection of the second stage.Figure 4: The decompiled output for the injection of the second stage.Second stageThe main purpose of the second stage is to inject the main instrumentation module. To increase stealthiness, the second stage of the loader employs more anti-analysis techniques using multiple modules. The modules have features that include a UAC bypass, Windows Defender Antivirus exclusion, using Heaven's Gate to execute x64 direct syscalls, and process hollowing.ModulesThe malware developers have continued to create new modules. The table below shows the HijackLoader modules added since our last blog.Hash ValueModule NameDescription8858AC11modCreateProcessThis module takes a pointer to an array as an argument. This array contains lpCommandLine, dwCreationFlags, lpStartupInfo, and lpProcessInformation which is used to create the new process.9757C10FmodCreateProcess64This module is the 64-bit version of modCreateProcess.3B2859F5modUACThis module also takes a pointer to an array as an argument. It is used to bypass UAC using the CMSTPLUA COM interface. If a UAC bypass is required, there will be an additional module called UACDATA containing additional data required to perform the UAC bypass.7366BCF3modUAC64This module is the 64-bit version of modUAC.4F7A1A39modWriteFileThis module also takes a pointer to an array as an argument. This array contains an XOR key, source address, destination address, and data size. The source data is XOR’ed with the key and copied to the destination address. The destination address (which contains the decrypted data) and data size are given as arguments to WriteFile.1C549B37modWriteFile64This module is the 64-bit version of modWriteFile.1003C017WDDATAThis module contains a PowerShell command to add a Windows Defender Antivirus exclusion.Table 2: The new modules added to HijackLoader.ti moduleThe ti module is the first module called by the first stage. It dynamically resolves APIs by walking the PEB and parsing PE headers using CRC-32 as a hashing algorithm. It then checks if a mutex, whose name is resolved using CRC-32 hashing, is present on the system. If the mutex is present, the process terminates; otherwise, it continues execution.Next, the ti module retrieves the environment variable at offset 0x45 from the decompressed data (%APPDATA% in our case), expands it, and checks if the current process is running under this directory. If not, it copies itself to this location, executes the copied file, and terminates itself.Next, the loader uses the Heaven's Gate technique to bypass user mode hooks – this is further explored in the next section.Bypass user mode hooks for injectionTo bypass user mode hooks, the loader uses a combination of Heaven's Gate and a direct syscall technique. The screenshot below shows HijackLoader employing the Heaven’s Gate technique to execute an x64 direct syscall.Figure 5: HijackLoader using Heaven’s Gate to execute a x64 direct syscall.Subsequently, the execution is returned to the 32-bit code. Following this, the next stage is injected. The process designated for injection is stored in the decompressed data at offset 0x90 (%windir%\SysWOW64\cmd.exe in our specific case). The cmd.exe is created as a child process, and the main instrumentation module is injected using process hollowing. The main instrumentation module uses the same process mentioned in our previous blog to decrypt the final payload and execute it.Malware DeliveryIn March 2024, ThreatLabz researchers analyzed around 50 samples of HijackLoader with an embedded PNG to identify which families are currently distributed by HijackLoader.HijackLoader was used to distribute the following malware:Amadey: Trojan that collects data about the victim’s system and is capable of loading other malware. Amadey emerged as the most prevalent family delivered by HijackLoader, comprising 52.9% of observed instances—a notable margin above other malware families. Lumma Stealer (aka LummaC2 Stealer): Information stealer that steals data from items like cryptocurrency wallets, steam accounts, KeePass, FileZilla, and browser extensions.Racoon Stealer v2: Information stealer that steals data such as saved passwords, cookies, auto-fill data, and cryptocurrency wallets.Remcos: Remote Access Trojan (RAT) used to gain backdoor access to a victim’s system.Meta Stealer: Information stealer that targets browsers, cryptocurrency wallets, wallet extensions and steam accounts, and shares many similarities with Redline Stealer.Rhadamanthys: Information stealer that targets wallets, emails, note-keeping apps, and messengers.The figure below illustrates the distribution of malware families delivered by HijackLoader. Figure 6: A pie chart showing the different malware families distributed by HijackLoader.ConclusionHijackLoader has emerged as a significant threat, delivering multiple malware families such as Amadey, Lumma Stealer, Racoon Stealer v2, and Remcos RAT. Among these, Amadey has been the most commonly delivered family by HijackLoader. The loading of the second stage involves the use of an embedded PNG image or PNG image downloaded from the web, which is decrypted and parsed to load the ti module. Additionally, new modules have been integrated into HijackLoader, enhancing its capabilities and making it even more robust.To assist the research community in analyzing HijackLoader, we have created a Python script that is available in our GitHub repository. The script enables the decryption and decompression of the second stage, providing access to HijackLoader’s modules.ThreatLabz is actively monitoring this campaign and ensuring that Zscaler customers are protected from cybersecurity threats.Zscaler CoverageZscaler’s multilayered cloud security platform detects indicators related to HijackLoader at various levels. The screenshot below depicts the Zscaler Cloud Sandbox, showing detection details for HijackLoader.Figure 7: Zscaler Cloud Sandbox reportIn addition to sandbox detections, Zscaler’s multilayered cloud security platform detects indicators related to HijackLoader at various levels with the following threat names:Win64.Downloader.HijackLoaderWin32.Downloader.HijackLoaderW32/ABRisk.GXSZ-4158W64/ABRisk.UCRB-0609Win32.PWS.LummaWin32.Trojan.Lummastealer.XTIndicators Of Compromise (IOCs)Host indicatorsTypeIndicator(s)DescriptionSHA2567a8db5d75ca30164236d2474a4719046a7814a4411cf703ffb702bf6319939d7d95e82392d720911f7eb5d8856b8ccd2427e51645975cdf8081560c2f6967ffb'fcadcee5388fa2e6d4061c7621bf268cb3d156cb879314fa2f518d15f5fa2aa2f37b158b3b3c6ef9f6fe08d0056915fc7e5a220d1dabb6a2b62364ae54dca0f1e0a4f1c878f20e70143b358ddaa28242bac56be709b5702f3ad656341c54fb76cf42af2bdcec387df84ba7f8467bbcdad9719df2c524b6c9b7fffa55cfdc8844c215c0838b1f8081a11ff3050d12fcfe67f14442ed2e18398f0c26c47931df449b15cb2782f953090caf76efe974c4ef8a5f28df3dbb3eff135d44306d80c29c56fd2541a36680249ec670d07a5682d2ef5a343d1feccbcf2c3da86bd546af851fbf01b3cb97fda61a065891f03dca7ed9187a4c1d0e8c5f24ef0001884a54daHijackLoader malware which uses an embedded PNGto load the next stage. Network indicatorsTypeIndicatorDescriptionURLhxxp://discussiowardder[.]website/apiLummaStealer C2MITRE ATT&CK TechniquesIDTechnique NameTA0002ExecutionT1547.001Boot or Logon Autostart Execution Registry Run Keys / Startup FolderT1548.001Abuse Elevation Control MechanismT1027.007Dynamic API ResolutionT1140Deobfuscate/Decode Files or InformationT1055Process InjectionT1620Reflective Code LoadingT1562.001Impair Defenses: Disable or Modify ToolsT1057Process DiscoveryAppendixVisit our GitHub repository to access the Python script to aid in your malware analysis.
Categories: Security Posts
Why Your VPN May Not Be As Secure As It Claims
Virtual private networking (VPN) companies market their services as a way to prevent anyone from snooping on your Internet usage. But new research suggests this is a dangerous assumption when connecting to a VPN via an untrusted network, because attackers on the same network could force a target’s traffic off of the protection provided by their VPN without triggering any alerts to the user.
Image: Shutterstock.
When a device initially tries to connect to a network, it broadcasts a message to the entire local network stating that it is requesting an Internet address. Normally, the only system on the network that notices this request and replies is the router responsible for managing the network to which the user is trying to connect.
The machine on a network responsible for fielding these requests is called a Dynamic Host Configuration Protocol (DHCP) server, which will issue time-based leases for IP addresses. The DHCP server also takes care of setting a specific local address — known as an Internet gateway — that all connecting systems will use as a primary route to the Web.
VPNs work by creating a virtual network interface that serves as an encrypted tunnel for communications. But researchers at Leviathan Security say they’ve discovered it’s possible to abuse an obscure feature built into the DHCP standard so that other users on the local network are forced to connect to a rogue DHCP server.
“Our technique is to run a DHCP server on the same network as a targeted VPN user and to also set our DHCP configuration to use itself as a gateway,” Leviathan researchers Lizzie Moratti and Dani Cronce wrote. “When the traffic hits our gateway, we use traffic forwarding rules on the DHCP server to pass traffic through to a legitimate gateway while we snoop on it.”
The feature being abused here is known as DHCP option 121, and it allows a DHCP server to set a route on the VPN user’s system that is more specific than those used by most VPNs. Abusing this option, Leviathan found, effectively gives an attacker on the local network the ability to set up routing rules that have a higher priority than the routes for the virtual network interface that the target’s VPN creates.
“Pushing a route also means that the network traffic will be sent over the same interface as the DHCP server instead of the virtual network interface,” the Leviathan researchers said. “This is intended functionality that isn’t clearly stated in the RFC [standard]. Therefore, for the routes we push, it is never encrypted by the VPN’s virtual interface but instead transmitted by the network interface that is talking to the DHCP server. As an attacker, we can select which IP addresses go over the tunnel and which addresses go over the network interface talking to our DHCP server.”
Leviathan found they could force VPNs on the local network that already had a connection to arbitrarily request a new one. In this well-documented tactic, known as a DHCP starvation attack, an attacker floods the DHCP server with requests that consume all available IP addresses that can be allocated. Once the network’s legitimate DHCP server is completely tied up, the attacker can then have their rogue DHCP server respond to all pending requests.
“This technique can also be used against an already established VPN connection once the VPN user’s host needs to renew a lease from our DHCP server,” the researchers wrote. “We can artificially create that scenario by setting a short lease time in the DHCP lease, so the user updates their routing table more frequently. In addition, the VPN control channel is still intact because it already uses the physical interface for its communication. In our testing, the VPN always continued to report as connected, and the kill switch was never engaged to drop our VPN connection.”
The researchers say their methods could be used by an attacker who compromises a DHCP server or wireless access point, or by a rogue network administrator who owns the infrastructure themselves and maliciously configures it. Alternatively, an attacker could set up an “evil twin” wireless hotspot that mimics the signal broadcast by a legitimate provider.
ANALYSIS
Bill Woodcock is executive director at Packet Clearing House, a nonprofit based in San Francisco. Woodcock said Option 121 has been included in the DHCP standard since 2002, which means the attack described by Leviathan has technically been possible for the last 22 years.
“They’re realizing now that this can be used to circumvent a VPN in a way that’s really problematic, and they’re right,” Woodcock said.
Woodcock said anyone who might be a target of spear phishing attacks should be very concerned about using VPNs on an untrusted network.
“Anyone who is in a position of authority or maybe even someone who is just a high net worth individual, those are all very reasonable targets of this attack,” he said. “If I were trying to do an attack against someone at a relatively high security company and I knew where they typically get their coffee or sandwich at twice a week, this is a very effective tool in that toolbox. I’d be a little surprised if it wasn’t already being exploited in that way, because again this isn’t rocket science. It’s just thinking a little outside the box.”
Successfully executing this attack on a network likely would not allow an attacker to see all of a target’s traffic or browsing activity. That’s because for the vast majority of the websites visited by the target, the content is encrypted (the site’s address begins with https://). However, an attacker would still be able to see the metadata — such as the source and destination addresses — of any traffic flowing by.
KrebsOnSecurity shared Leviathan’s research with John Kristoff, founder of dataplane.org and a PhD candidate in computer science at the University of Illinois Chicago. Kristoff said practically all user-edge network gear, including WiFi deployments, support some form of rogue DHCP server detection and mitigation, but that it’s unclear how widely deployed those protections are in real-world environments.
“However, and I think this is a key point to emphasize, an untrusted network is an untrusted network, which is why you’re usually employing the VPN in the first place,” Kristoff said. “If [the] local network is inherently hostile and has no qualms about operating a rogue DHCP server, then this is a sneaky technique that could be used to de-cloak some traffic – and if done carefully, I’m sure a user might never notice.”
MITIGATIONS
According to Leviathan, there are several ways to minimize the threat from rogue DHCP servers on an unsecured network. One is using a device powered by the Android operating system, which apparently ignores DHCP option 121.
Relying on a temporary wireless hotspot controlled by a cellular device you own also effectively blocks this attack.
“They create a password-locked LAN with automatic network address translation,” the researchers wrote of cellular hot-spots. “Because this network is completely controlled by the cellular device and requires a password, an attacker should not have local network access.”
Leviathan’s Moratti said another mitigation is to run your VPN from inside of a virtual machine (VM) — like Parallels, VMware or VirtualBox. VPNs run inside of a VM are not vulnerable to this attack, Moratti said, provided they are not run in “bridged mode,” which causes the VM to replicate another node on the network.
In addition, a technology called “deep packet inspection” can be used to deny all in- and outbound traffic from the physical interface except for the DHCP and the VPN server. However, Leviathan says this approach opens up a potential “side channel” attack that could be used to determine the destination of traffic.
“This could be theoretically done by performing traffic analysis on the volume a target user sends when the attacker’s routes are installed compared to the baseline,” they wrote. “In addition, this selective denial-of-service is unique as it could be used to censor specific resources that an attacker doesn’t want a target user to connect to even while they are using the VPN.”
Moratti said Leviathan’s research shows that many VPN providers are currently making promises to their customers that their technology can’t keep.
“VPNs weren’t designed to keep you more secure on your local network, but to keep your traffic more secure on the Internet,” Moratti said. “When you start making assurances that your product protects people from seeing your traffic, there’s an assurance or promise that can’t be met.”
A copy of Leviathan’s research, along with code intended to allow others to duplicate their findings in a lab environment, is available here.
Categories: Security Posts
Introducing LevelBlue: Elevating Business Confidence By Simplifying Security
Today is a monumental day for the cybersecurity industry. Live from RSA Conference 2024, I’m excited to introduce LevelBlue – a joint venture with AT&T and WillJam Ventures, to form a new, standalone managed security services business. You can read more about the news here.
In 2022, I founded my private equity firm, WillJam Ventures, and since then, we’ve held an exceptional track record of investing in and operating world-class cybersecurity businesses. This latest investment in LevelBlue is no exception, serving as further testament to this commitment. We’re excited about the opportunity ahead for LevelBlue. Here’s why:
● Its mission – to simplify security and make cyber resilience an attainable outcome – is critical to business success. As organizations continue innovating, technologies such as artificial intelligence (AI) and cloud computing create a more dynamic, expanded threat landscape. With LevelBlue, organizations no longer need to sacrifice innovation with security – they achieve both, with confidence. With more than 1,300 employees focused on this mission, LevelBlue offers strategic security services including award-winning managed security services, experienced strategic consulting, threat intelligence and groundbreaking research – serving as a trusted advisor to businesses worldwide.
● LevelBlue brings together some of the most talented, brightest minds in cybersecurity. Just like any journey, organizations should not embark on their cybersecurity journey alone. This is where LevelBlue comes in. Every member of our consulting team has an average of 15 years of experience in cybersecurity, holding the latest certifications and knowledge in working with organizations of various types and sizes. I’m also excited to be joined by Sundhar Annamalai, the president of LevelBlue, who has more than 20 years of experience in technology services and strategic execution to help take our company to new heights.
● The company has a longstanding history of delivering forward-looking, vendor-neutral research. Trusted advisors keep their clients informed on the latest trends before they happen, and that is what LevelBlue is best at. With the LevelBlue threat intelligence platform, as well as the company’s industry-leading research reports (more to come on this blog), clients can stay one-step ahead of the latest cyber threats, while gaining valuable insights into how to properly allocate cybersecurity resources.
Cyber resiliency is not easily defined, nor is it easily attainable without the necessary support. LevelBlue’s strategic cybersecurity services will help solve this challenge during a time when it’s needed most. We have the right team, the right technology, and at the right moment in time – I’m thrilled for the journey ahead.
For those at RSA Conference, we invite you to come learn more about LevelBlue by visiting booth #6155 at Moscone North Expo. We look forward to introducing ourselves to you.
Categories: Security Posts
The life and times of an Abstract Syntax Tree
By Francesco Bertolaccini
You’ve reached computer programming nirvana. Your journey has led you down many paths, including believing that God wrote the universe in LISP, but now the truth is clear in your mind: every problem can be solved by writing one more compiler.
It’s true. Even our soon-to-be artificially intelligent overlords are nothing but compilers, just as the legends foretold. That smart contract you’ve been writing for your revolutionary DeFi platform? It’s going through a compiler at some point.
Now that we’ve established that every program should contain at least one compiler if it doesn’t already, let’s talk about how one should go about writing one. As it turns out, this is a pretty vast topic, and it’s unlikely I’d be able to fit a thorough disquisition on the subject in the margin of this blog post. Instead, I’m going to concentrate on the topic of Abstract Syntax Trees (ASTs).
In the past, I’ve worked on a decompiler that turns LLVM bitcode into Clang ASTs, and that has made me into someone with opinions about them. These are opinions on the things they don’t teach you in school, like: what should the API for an AST look like? And how should it be laid out in memory? When designing a component from scratch, we must consider those aspects that go beyond its mere functionality—I guess you could call these aspects “pragmatics.” Let’s go over a few of them so that if you ever find yourself working with ASTs in the future, you may skip the more head-scratching bits and go straight to solving more cogent problems!
What are ASTs?
On their own, ASTs are not a very interesting part of a compiler. They are mostly there to translate the dreadful stream of characters we receive as input into a more palatable format for further compiler shenanigans. Yet the way ASTs are designed can make a difference when working on a compiler. Let’s investigate how.
Managing the unmanageable
If you’re working in a managed language like C# or Java, one with a garbage collector and a very OOP type system, your AST nodes are most likely going to look something like this:
class Expr {}
class IntConstant : Expr {
int value;
}
class BinExpr : Expr {
public Expr lhs;
public Expr rhs;
}
This is fine—it serves the purpose well, and the model is clear: since all of the memory is managed by the runtime, ownership of the nodes is not really that important. At the end of the day, those nodes are not going anywhere until everyone is done with them and the GC determines that they are no longer reachable.
(As an aside, I’ll be making these kinds of examples throughout the post; they are not meant to be compilable, only to provide the general idea of what I’m talking about.)
I typically don’t use C# or Java when working on compilers, though. I’m a C++ troglodyte, meaning I like keeping my footguns cocked and loaded at all times: since there is no garbage collector around to clean up after the mess I leave behind, I need to think deeply about who owns each and every one of those nodes.
Let’s try and mimic what was happening in the managed case.
The naive approach
struct Expr {
virtual ~Expr();
};
struct IntConstant : Expr {
int value;
};
struct BinExpr : Expr {
std::shared_ptr lhs;
std::shared_ptr rhs;
};
Shared pointers in C++ use reference counting (which one could argue is a form of automatic garbage collection), which means that the end result is similar to what we had in Java and C#: each node is guaranteed to stay valid at least until the last object holding a reference to it is alive.
That at least in the previous sentence is key: if this was an Abstract Syntax Graph instead of an Abstract Syntax Tree, we’d quickly find ourselves in a situation where nodes would get stuck in a limbo of life detached from material reality, a series of nodes pointing at each other in a circle, forever waiting for someone else to die before they can finally find their eternal rest as well.
Again, this is a purely academic possibility since a tree is by definition acyclic, but it’s still something to keep in mind.
I don’t know Rust that well, but it is my understanding that a layout roughly equivalent to the one above would be written like this:
enum Expr {
IntConstant(i32),
BinExpr(Arc<Expr>, Arc<Expr>)
}
When using this representation, your compiler will typically hold a reference to a root node that causes the whole pyramid of nodes to keep standing. Once that reference is gone, the rest of the nodes follow suit.
Unfortunately, each pointer introduces additional computation and memory consumption due to its usage of an atomic reference counter. Technically, one could avoid the “atomic” part in the Rust example by using Rc instead of Arc, but there’s no equivalent of that in C++ and my example would not work as well. In my experience, it’s quite easy to do away with the ceremony of making each node hold a reference count altogether, and instead decide on a more disciplined approach to ownership.
The “reverse pyramid” approach
struct Expr {
virtual ~Expr();
};
struct IntConstant : Expr {
int value;
};
struct BinExpr : Expr {
std::unique_ptr lhs;
std::unique_ptr rhs;
};
Using unique pointers frees us from the responsibility of keeping track of when to free memory without adding the overhead of reference counting. While it’s not possible for multiple nodes to have an owning reference to the same node, it’s still possible to express cyclic data structures by dereferencing the unique pointer and storing a reference instead. This is (very) roughly equivalent to using std::weak_ptr with shared pointers.
Just like in the naive approach, destroying the root node of the AST will cause all of the other nodes to be destroyed with it. The difference is that in this case we are guaranteed that this will happen, because every child node is owned by their parent and no other owning reference is possible.
I believe this representation is roughly equivalent to this Rust snippet:
enum Expr {
IntConstant(i32),
BinExpr(Box<Expr>, Box<Expr>)
}
Excursus: improving the API
We are getting pretty close to what I’d call the ideal representation, but one thing I like to do is to make my data structures as immutable as possible.
BinExpr would probably look like this if I were to implement it in an actual codebase:
class BinExpr : Expr {
std::unique_ptr lhs, rhs;
public:
BinExpr(std::unique_ptr lhs, std::unique_ptr rhs)
: lhs(std::move(lhs))
, rhs(std::move(rhs)) {}
const Expr& get_lhs() const { return *lhs; }
const Expr& get_rhs() const { return *rhs; }
};
This to me signals a few things:
- Nodes are immutable.
- Nodes can’t be null.
- Nodes can’t be moved; their owner is fixed.
- Use std::list.
- Use std::deque.
- Use indices instead of raw pointers.
Categories: Security Posts
Sifting through the spines: identifying (potential) Cactus ransomware victims
Authored by Willem Zeeman and Yun Zheng Hu
This blog is part of a series written by various Dutch cyber security firms that have collaborated on the Cactus ransomware group, which exploits Qlik Sense servers for initial access. To view all of them please check the central blog by Dutch special interest group Cyberveilig Nederland [1]
The effectiveness of the public-private partnership called Melissa [2] is increasingly evident. The Melissa partnership, which includes Fox-IT, has identified overlap in a specific ransomware tactic. Multiple partners, sharing information from incident response engagements for their clients, found that the Cactus ransomware group uses a particular method for initial access. Following that discovery, NCC Group’s Fox-IT developed a fingerprinting technique to identify which systems around the world are vulnerable to this method of initial access or, even more critically, are already compromised.
Qlik Sense vulnerabilities
Qlik Sense, a popular data visualisation and business intelligence tool, has recently become a focal point in cybersecurity discussions. This tool, designed to aid businesses in data analysis, has been identified as a key entry point for cyberattacks by the Cactus ransomware group.
The Cactus ransomware campaign
Since November 2023, the Cactus ransomware group has been actively targeting vulnerable Qlik Sense servers. These attacks are not just about exploiting software vulnerabilities; they also involve a psychological component where Cactus misleads its victims with fabricated stories about the breach. This likely is part of their strategy to obscure their actual method of entry, thus complicating mitigation and response efforts for the affected organizations.
For those looking for in-depth coverage of these exploits, the Arctic Wolf blog [3] provides detailed insights into the specific vulnerabilities being exploited, notably CVE-2023-41266, CVE-2023-41265 also known as ZeroQlik, and potentially CVE-2023-48365 also known as DoubleQlik.
Threat statistics and collaborative action
The scope of this threat is significant. In total, we identified 5205 Qlik Sense servers, 3143 servers seem to be vulnerable to the exploits used by the Cactus group. This is based on the initial scan on 17 April 2024. Closer to home in the Netherlands, we’ve identified 241 vulnerable systems, fortunately most don’t seem to have been compromised. However, 6 Dutch systems weren’t so lucky and have already fallen victim to the Cactus group. It’s crucial to understand that “already compromised” can mean that either the ransomware has been deployed and the initial access artifacts left behind were not removed, or the system remains compromised and is potentially poised for a future ransomware attack.
Since 17 April 2024, the DIVD (Dutch Institute for Vulnerability Disclosure) and the governmental bodies NCSC (Nationaal Cyber Security Centrum) and DTC (Digital Trust Center) have teamed up to globally inform (potential) victims of cyberattacks resembling those from the Cactus ransomware group. This collaborative effort has enabled them to reach out to affected organisations worldwide, sharing crucial information to help prevent further damage where possible.
Identifying vulnerable Qlik Sense servers
Expanding on Praetorian’s thorough vulnerability research on the ZeroQlik and DoubleQlik vulnerabilities [4,5], we found a method to identify the version of a Qlik Sense server by retrieving a file called product-info.json from the server. While we acknowledge the existence of Nuclei templates for the vulnerability checks, using the server version allows for a more reliable evaluation of potential vulnerability status, e.g. whether it’s patched or end of support.
This JSON file contains the release label and version numbers by which we can identify the exact version that this Qlik Sense server is running.
Figure 1: Qlik Sense product-info.json file containing version information
Keep in mind that although Qlik Sense servers are assigned version numbers, the vendor typically refers to advisories and updates by their release label, such as “February 2022 Patch 3”.
The following cURL command can be used to retrieve the product-info.json file from a Qlik server:
curl -H "Host: localhost" -vk 'https://<ip>/resources/autogenerated/product-info.json?.ttf'
Note that we specify ?.ttf at the end of the URL to let the Qlik proxy server think that we are requesting a .ttf file, as font files can be accessed unauthenticated. Also, we set the Host header to localhost or else the server will return 400 - Bad Request - Qlik Sense, with the message The http request header is incorrect.
Retrieving this file with the ?.ttf extension trick has been fixed in the patch that addresses CVE-2023-48365 and you will always get a 302 Authenticate at this location response:
> GET /resources/autogenerated/product-info.json?.ttf HTTP/1.1
> Host: localhost
> Accept: */*
>
< HTTP/1.1 302 Authenticate at this location
< Cache-Control: no-cache, no-store, must-revalidate
< Location: https://localhost/internal_forms_authentication/?targetId=2aa7575d-3234-4980-956c-2c6929c57b71
< Content-Length: 0
<
Nevertheless, this is still a good way to determine the state of a Qlik instance, because if it redirects using 302 Authenticate at this location it is likely that the server is not vulnerable to CVE-2023-48365.
An example response from a vulnerable server would return the JSON file:
> GET /resources/autogenerated/product-info.json?.ttf HTTP/1.1
> Host: localhost
> Accept: */*
>
< HTTP/1.1 200 OK
< Set-Cookie: X-Qlik-Session=893de431-1177-46aa-88c7-b95e28c5f103; Path=/; HttpOnly; SameSite=Lax; Secure
< Cache-Control: public, max-age=3600
< Transfer-Encoding: chunked
< Content-Type: application/json;charset=utf-8
< Expires: Tue, 16 Apr 2024 08:14:56 GMT
< Last-Modified: Fri, 04 Nov 2022 23:28:24 GMT
< Accept-Ranges: bytes
< ETag: 638032013040000000
< Server: Microsoft-HTTPAPI/2.0
< Date: Tue, 16 Apr 2024 07:14:55 GMT
< Age: 136
<
{"composition":{"contentHash":"89c9087978b3f026fb100267523b5204","senseId":"qliksenseserver:14.54.21","releaseLabel":"February 2022 Patch 12","originalClassName":"Composition","deprecatedProductVersion":"4.0.X","productName":"Qlik Sense","version":"14.54.21","copyrightYearRange":"1993-2022","deploymentType":"QlikSenseServer"},
<snipped>
We utilised Censys and Google BigQuery [6] to compile a list of potential Qlik Sense servers accessible on the internet and conducted a version scan against them. Subsequently, we extracted the Qlik release label from the JSON response to assess vulnerability to CVE-2023-48365.
Our vulnerability assessment for DoubleQlik / CVE-2023-48365 operated on the following criteria:
We shared our fingerprints and scan data with the Dutch Institute of Vulnerability Disclosure (DIVD), who then proceeded to issue responsible disclosure notifications to the administrators of the Qlik Sense servers. Call to action Ensure the security of your Qlik Sense installations by checking your current version. If your software is still supported, apply the latest patches immediately. For systems that are at the end of support, consider upgrading or replacing them to maintain robust security. Additionally, to enhance your defences, it’s recommended to avoid exposing these services to the entire internet. Implement IP whitelisting if public access is necessary, or better yet, make them accessible only through secure remote working solutions. If you discover you’ve been running a vulnerable version, it’s crucial to contact your (external) security experts for a thorough check-up to confirm that no breaches have occurred. Taking these steps will help safeguard your data and infrastructure from potential threats. References
{kind=link}
- The release label corresponds to vulnerability statuses outlined in the original ZeroQlik and DoubleQlik vendor advisories [7,8].
- The release label is designated as End of Support (EOS) by the vendor [9], such as “February 2019 Patch 5”.
- The release label date is post-November 2023, as the advisory states that “November 2023” is not affected.
- The server responded with HTTP/1.1 302 Authenticate at this location.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
We shared our fingerprints and scan data with the Dutch Institute of Vulnerability Disclosure (DIVD), who then proceeded to issue responsible disclosure notifications to the administrators of the Qlik Sense servers. Call to action Ensure the security of your Qlik Sense installations by checking your current version. If your software is still supported, apply the latest patches immediately. For systems that are at the end of support, consider upgrading or replacing them to maintain robust security. Additionally, to enhance your defences, it’s recommended to avoid exposing these services to the entire internet. Implement IP whitelisting if public access is necessary, or better yet, make them accessible only through secure remote working solutions. If you discover you’ve been running a vulnerable version, it’s crucial to contact your (external) security experts for a thorough check-up to confirm that no breaches have occurred. Taking these steps will help safeguard your data and infrastructure from potential threats. References
- https://cyberveilignederland.nl/actueel/persbericht-samenwerkingsverband-melissa-vindt-diverse-nederlandse-slachtoffers-van-ransomwaregroepering-cactus ︎
- https://www.ncsc.nl/actueel/nieuws/2023/oktober/3/melissa-samenwerkingsverband-ransomwarebestrijding ︎
- https://arcticwolf.com/resources/blog/qlik-sense-exploited-in-cactus-ransomware-campaign/ ︎
- https://www.praetorian.com/blog/qlik-sense-technical-exploit/ ︎
- https://www.praetorian.com/blog/doubleqlik-bypassing-the-original-fix-for-cve-2023-41265/ ︎
- https://support.censys.io/hc/en-us/articles/360038759991-Google-BigQuery-Introduction ︎
- https://community.qlik.com/t5/Official-Support-Articles/Critical-Security-fixes-for-Qlik-Sense-Enterprise-for-Windows/ta-p/2110801 ︎
- https://community.qlik.com/t5/Official-Support-Articles/Critical-Security-fixes-for-Qlik-Sense-Enterprise-for-Windows/ta-p/2120325 ︎
- https://community.qlik.com/t5/Product-Lifecycle/Qlik-Sense-Enterprise-on-Windows-Product-Lifecycle/ta-p/1826335 ︎
Categories: Security Posts
Cybersecurity Concerns for Ancillary Strength Control Subsystems
Additive manufacturing (AM) engineers have been incredibly creative in developing ancillary systems that modify a printed parts mechanical properties. These systems mostly focus on the issue of anisotropic properties of additively built components. This blog post is a good reference if you are unfamiliar with isotropic vs anisotropic properties and how they impact 3d printing. […]
The post Cybersecurity Concerns for Ancillary Strength Control Subsystems appeared first on BreakPoint Labs - Blog.
Categories: Security Posts
Update on Naked Security
To consolidate all of our security intelligence and news in one location, we have migrated Naked Security to the Sophos News platform.
Categories: Security Posts